What happens when a boot disk fails on a vSAN host?
Have you ever wondered what would happen if an ESXi host lost access to its boot disk? If you expect the host to throw a purple screen of death and all VMs to be restarted on another host by vSphere HA, you might be surprised to find that the host will continue to operate more or less as usual, and virtual machines running on the host will continue to function without any problems.
The reason ESXi continues to function in this state is that ESXi runs in-memory after boot, and only uses the boot volume for saving persistent configuration changes and writing log files. In fact, vSphere Auto Deploy allows ESXi hosts to be booted via TFTP and run without any local installation of ESXi at all, although you can also enable a stateful configuration (where ESXi gets installed to a local disk) as well. However, stateless mode is not supported with vSAN, and if you’re using Auto Deploy to build your hosts you must configure stateful mode for vSAN compatibility.
A customer recently asked me to quantify the impact to availability and manageability in their environment if they lost a boot disk. The customer had originally wanted to go with a design that had redundant boot disks configured in a RAID1 volume, however due to hardware constraints this RAID1 configuration had to be scrapped and each ESXi host would boot off a single SDD. As I’ve said, running a vSAN host without a boot disk is not a supported configuration, but supportability aside I thought it would be interesting to dig a little deeper and demonstrate what happens in this scenario.
Initial state
I’ve got a virtualised 3-node vSphere cluster with vSAN enabled. I’ll remove the boot disk from one of the hosts, and do a few simple tests:
- Changing host config
- Creating a virtual machine and installing an OS
- Vmotioning the virtual machine to another host and back again
Here’s my cluster. All is looking healthy. The three disks shown in the list of Storage Devices on virt-esxi01 in order are the boot, vSAN cache, and vSAN capacity disks.
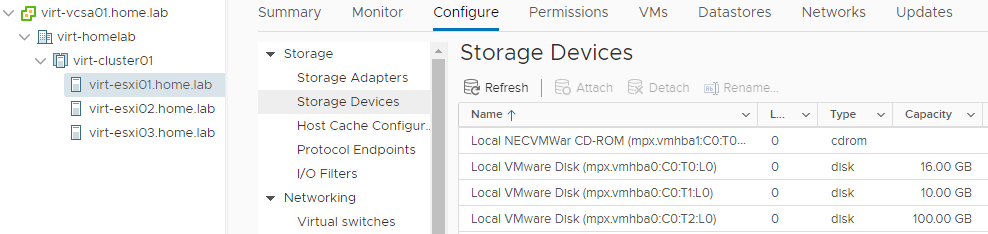
I’ve now removed the boot disk from virt-esxi01. Note the host is now reporting a warning, and the disk is listed greyed out and in italics with a status (not pictured) of “Dead or Error”.
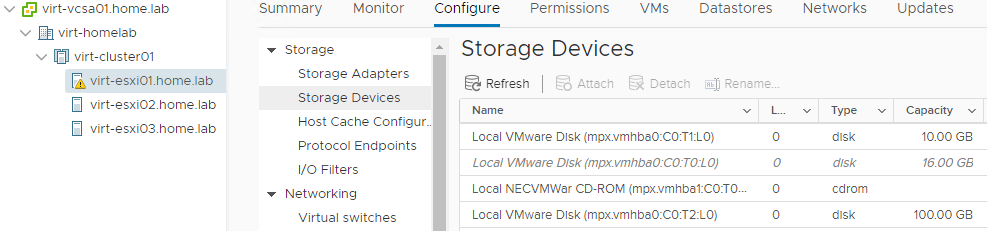
If I take a look at the Summary page on the host, I’ll see the following warning message:
Lost connectivity to the device mpx.vmhba0:C0:T0:L0 backing the boot filesystem /vmfs/devices/disks/mpx.vmhba0:C0:T0:L0. As a result, host configuration changes will not be saved to persistent storage.
The key thing here: host configuration changes will not be saved to persistent storage. This means if I reboot the host, any configuration change I make will be gone. Of course, if the boot disk has failed, there are bigger problems if I reboot the host: it will not be able to boot again as there is nothing to boot from.
1. Changing host config
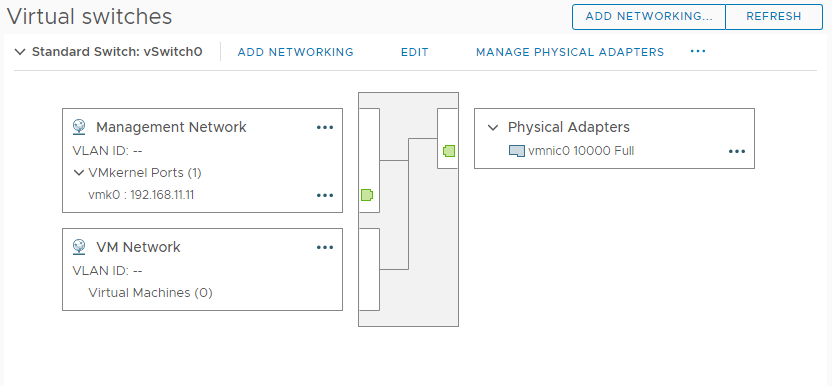
This is to test whether I can apply configuration changes to an ESXi host in this state. I’m going to add the host to a vsphere distributed switch (VDS), create a new vmkernel port on the host, and connect the vmkernel port to a port group on the new VDS. Below is the existing network configuration on the host, with just the default vSwitch0 present:
After creating the new VDS, adding the host, and creating a new vmkernel port with an IP address of 10.1.1.1, you can see the results below. The warning message is simply a result of having no physical NICs assigned as uplinks to the VDS, and nothing to do with the missing boot disk. The point is, there is no problem with updating host’s configuration in this state, except that the configuration change will not persist across reboots as there is nowhere to store the configuration change to.
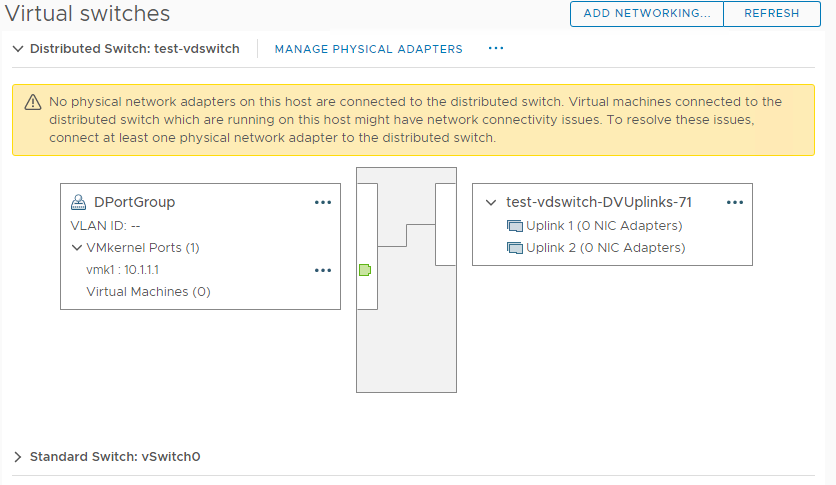
2. Creating a virtual machine and installing an OS
This tests a few things: whether I can create & register a virtual machine on the host, whether I can attach it to a network, whether I can access the vSAN datastore, and whether I can complete the OS installation process.
I’ve created a virtual machine called ubuntu01 on virt-esxi01 and powered it on. So far so good.
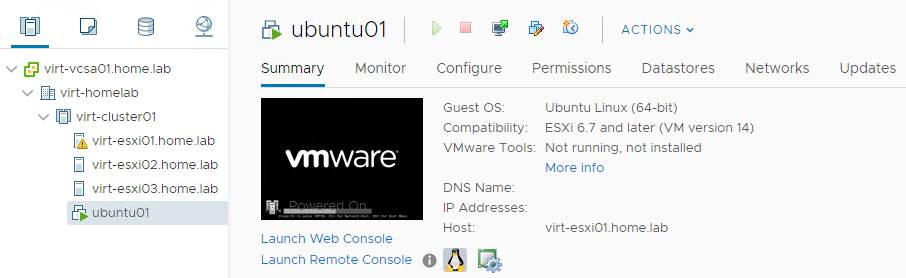
I’ve then mounted the ubuntu server .iso from my local client and started the installation process. After configuring an IP address during the installation process, the virtual machine responds to ping. After completing the installation of ubuntu server, VMware Tools is also detected and running.
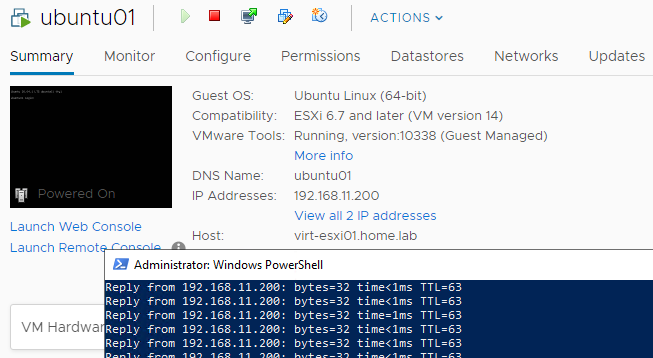
3. Vmotioning the virtual machine to another host and back again
This is a useful test as if a boot disk fails on a host in a production environment, you want to know that you can vmotion the virtual machines onto another host before shutting down the impacted host to replace the boot disk. I vmotioned the ubuntu01 virtual machine from virt-esxi01 to virt-esxi02 and back again. The easiest way to demonstrate this in a single screenshot is the task log for the migration event back onto virt-esxi01 which is found under Monitor > Tasks and Events > Tasks:
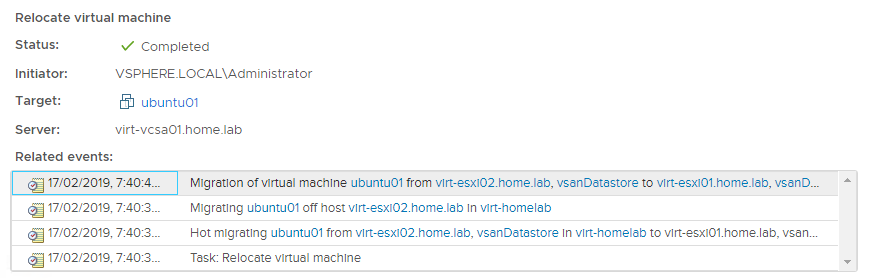
Conclusion
I suppose the main takeaway from this is that an ESXi host losing a boot disk isn’t by itself the end of the world, even in a vSAN cluster where it’s not actually supported. If this happens to you in a production environment, you’ve got time to safely migrate running virtual machines off the host before putting it into maintenance mode and replacing the part. If this happens in a dev environment, or an environment which is extremely resource constrained, you could even consider leaving the host out of maintenance mode until the replacement part is ready for installation.
The second thing to consider is whether it’s really necessary to have redundant boot disks in a RAID1 volume. Ultimately, this will come down to your risk tolerance, your environment, and your budget. If you’re installing ESXi onto a USB key or SD card, by all means configure a redundant pair of these into a RAID1 volume (if the hardware supports it), as these devices tend to have a shorter lifespan relative to a HDD or SSD, and I’ve also seen them fail in batches more frequently than other types of drives. In other cases however, it’s worth considering whether redundant boot is a must have, or whether the budget on those extra disks, as small is it may be, could be better spent elsewhere.
comments powered by Disqus